
In the fast-paced world of cloud computing, ensuring the security and reliability of systems is critical. Chaos engineering, a practice designed to test system resilience by introducing controlled failures, has emerged as a vital strategy for modern cloud environments. Let’s explore how chaos engineering enhances cloud security and reliability and why it’s becoming a must-have practice for organizations.
What is Chaos Engineering?
Chaos engineering is the disciplined approach of intentionally injecting failures into systems to uncover weaknesses before they lead to major outages. Popularized by tech giants like Netflix, chaos engineering involves experiments that mimic real-world disruptions, such as server failures, network outages, and resource constraints. The goal is to test how systems respond and adapt under stress.
Why Chaos Engineering in the Cloud?
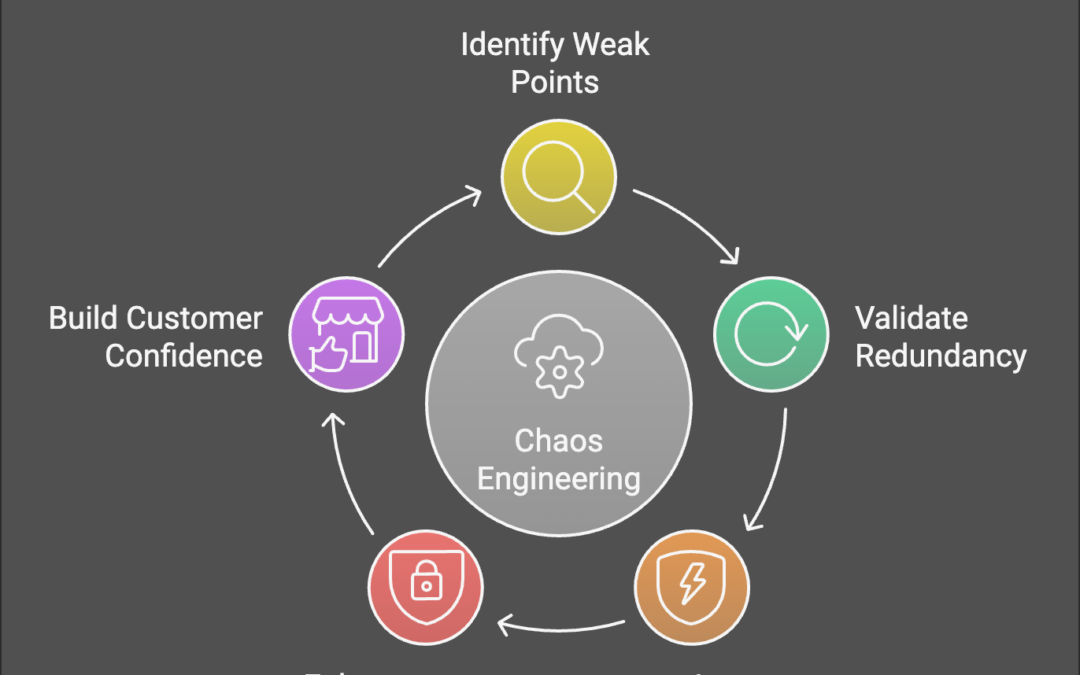
Cloud environments are inherently complex and dynamic, making them prone to unexpected failures. Chaos engineering helps cloud practitioners:
- Identify Weak Points: Simulate potential failure scenarios to find vulnerabilities in your cloud infrastructure.
- Validate Redundancy and Failover Mechanisms: Ensure that multi-region deployments and backup systems work as intended.
- Improve Incident Response: Train teams to handle real-world disruptions effectively by simulating them in a controlled manner.
- Enhance Security Posture: Test how systems handle security incidents, such as DDoS attacks or data breaches, without compromising real operations.
- Build Customer Confidence: Demonstrate proactive measures to maintain reliability and security, which builds trust.
Key Steps in Cloud Chaos Engineering
- Define the “Steady State”: Identify metrics that indicate your system is operating normally, such as uptime, response time, or error rates.
- Plan Experiments: Choose scenarios that could disrupt the steady state, such as network latency spikes or database failures.
- Introduce Controlled Chaos: Use tools to simulate these failures in a staged manner. Popular tools include Gremlin, Chaos Monkey, and LitmusChaos.
- Monitor System Response: Observe how your system reacts. Did it recover? Were users impacted?
- Learn and Iterate: Document findings, fix vulnerabilities, and refine the system to better handle future disruptions.
Real-World Use Cases
- Netflix: Originator of the Chaos Monkey tool, Netflix uses chaos engineering to ensure its streaming platform remains reliable even during failures.
- Amazon Web Services (AWS): AWS employs chaos testing to validate the robustness of its multi-region and availability zone setups.
- Financial Institutions: Banks simulate database outages and transaction delays to validate their disaster recovery and failover mechanisms.
Best Practices for Chaos Engineering in the Cloud
- Start Small: Begin with non-critical systems to avoid unintended large-scale disruptions.
- Automate Experiments: Use tools to schedule and execute chaos scenarios consistently.
- Collaborate Across Teams: Involve operations, security, and development teams to gain holistic insights.
- Focus on Security: Test for vulnerabilities that could arise during system failures, such as unauthorized access or data corruption.
- Measure Success: Use metrics like mean time to recovery (MTTR) and service uptime to gauge improvements.
The Future of Chaos Engineering
As cloud environments evolve with trends like serverless computing, edge deployments, and AI-driven operations, chaos engineering will play a critical role in maintaining security and reliability. By continuously testing and adapting, organizations can stay resilient in an ever-changing landscape.
Conclusion
Chaos engineering is not just about breaking things; it’s about building stronger systems. By proactively identifying and addressing vulnerabilities, organizations can ensure their cloud environments remain secure and reliable, even in the face of unexpected challenges. Embracing chaos engineering today means fewer surprises and greater confidence tomorrow.